With the end of the transfer window looming and many supporters calling for Arsene to reinforce the squad with new additions, I thought I’d look at the age range of Arsenal’s current EPL squad including some on loan. Obviously age isn’t the prime criterion when assessing a player, but it is the significant indicator in terms of longevity and therefore team development.
When Arsene was asked recently about the signing of Elneny, he praised his attributes and added in characteristic fashion that he was 23 and that 23 to 30 was an ‘interesting’ age for a footballer. We all know what he meant by this. For all but one position, 23-30 would be considered the peak years of a player’s career. The exception is the keeper, where experience is crucial and the toll on the body is less, meaning that they can remain at the top of their game into their late thirties … and guess what ….. we’ve got one of those!
In the past, it was the case that centre backs could still be at their peak into their early thirties, but I would argue that the pace and physical demands of the modern game mean this is seldom the case nowadays. Hopefully Koscielny will prove to be the exception to that rule, sadly it is becoming apparent that Mertesacker is not.
I don’t expect us to sign another ‘first team ready’ player before the deadline on Monday, and maybe the stats below will convince you that we don’t need to.
The area marked in yellow in the chart below represents the age group of those who are considered to be in their peak years (Bellerin is the exception to that rule) . The names in red are unlikely to be with us next season, and those in green are currently out on loan but a good prospect for the future.
I have divided the midfielders into 3 categories just so the pedants among you can tell me I’m wrong 🙂
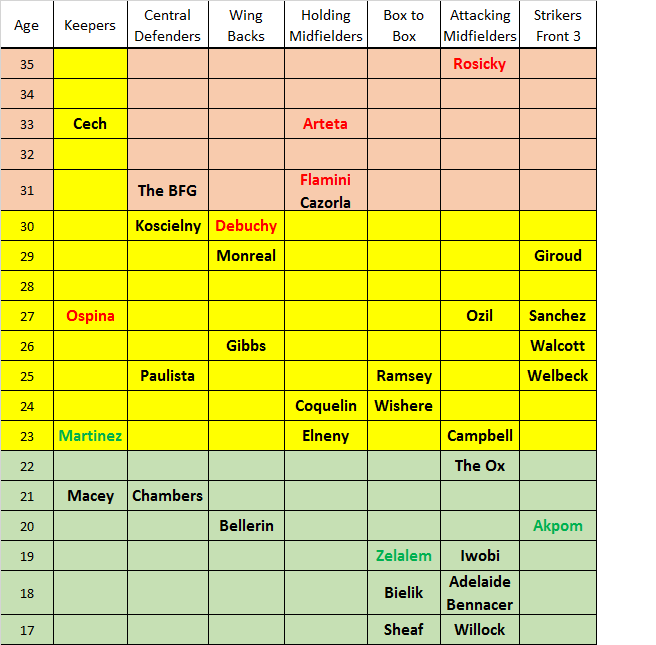
In an ideal world, the first choice players in every position would be in their peak years – in fact it would be perfect if the second choice option was also in the 23-30 zone.
But that’s not how it works, the top players are in the zone and the back up is either younger hoping to break into the team, or older and with lower expectation. This theory is backed up by the fact that both Ospina and Debuchy are in their peak years, neither are first choice and both want to leave – and who can blame them?
By my estimation, 8 out of 10 of our first choice outfield players are at their peak in terms of age. That’s pretty good and I suspect compares favourably with the other top EPL sides.
So which areas should we be looking to reinforce in the summer?
Martinez is currently gaining experience on loan at Wolves and may be the man to take over from Cech in a few years. We have a wealth of talented young attacking midfielders waiting for their chance to make an impact on the first eleven. Unluckily for them, most of the current incumbents are at the perfect age.
Arguably centre back and striker are the two areas where we could be vulnerable. With Mertesacker coming to the end of his career, and only Chambers as back-up I can see procuring another CB as a priority. As far as strikers are concerned, we will only be able to assess that situation once we have seen Welbeck stay injury free and get a run of games. If he can replicate the form he showed before he was injured then Arsene may well believe we don’t need another striker. Personally, I’d be happy to blow £50-60m if the right striker became available in the summer.
Your challenge for today ……. convince me we need to buy another player this January!
Rasp
 Arsenal News 24/7
Arsenal News 24/7

simply because we were not able to score against shiiiiit teams like the orcs and the chavs
Superb Rasp
We love a chart as much as a heat map.
I don’t think anyone needs convincing “we need to buy another player this January”, but even I’d admit it may be quite difficult to get hold of someone good enough to go straight into the First XI and make a difference.
I just hope they’re trying to find that attacker 🙂
Rasp. Excellent chart. Colours and everything….
Age wise we are in fine shape which is no accident. AW has made this a priority for sometime.
If available I would buy Stones from Everton for any money. He has a touch of the TA about him and we need a Captain going forward.
Oh and we should buy Gareth Bale. Not just because he would improve the team but also to announce to the rest of the world that we dine at the top table
Welcome Sampan – I’m afraid I have to give the obvious response … who do you have in mind? Where will we get an EPL ready striker who is guaranteed to start scoring goals for us in the remaining 14 games?
Micky, P.E.A. would be the striker for me in the summer although we’d have to fight off the other contenders. Today’s internet lie is that we’ve done the deal to sign Yarmolenko in the summer.
Raddy, I agree 100% about Stones but reckon he’s not going to choose us. It’s thought that Cahill will be leaving the chavs in the summer …. could you see him in the red and white?
Trouble posting with wordpress, so incase my long reply is lost here’s a short one! … Great useful table: I suspect Wenger and team have a version of it. Obvious challenge is that age isn’t everything: if we can get an upgrade in ability and potential we ought to (Bale and Aguero for Chamberlain and Welbeck!). Your wingback column makes us look strong but if you break it out into left and right – on the right we are likely to have just Bellerin.
Oh, and Bielik is in the wrong column – he played DM at last club and has been used as a CB recently too. Love to see this table against other clubs and enlarged to include all the academy.
Wheres Sczezney
Hi Simon and welcome. Yes I make the reference to age only in relation to longevity, obviously quality is always the first concern and there are areas where we might hope to bring in better quality.
I am assuming that AW considers Chambers can fill in at RB if he is planning to let Debuchy go this window. The sad thing is that we don’t seem to have many quality defenders coming up through the academy.
Hi Matt, I left Szczesny out on purpose as I believe he won’t be coming back and will be sold. It looks to me as though Martinez is being lined up to take over from Sz as back-up to Cech. For all his talent, Sz’s decision making on and off the pitch lets him down. There are some character traits which cannot be suppressed.
Promise this will be a one off, then back to Rasp’s post, but this exchange from earlier has to be one of my all time favourites:
Big Raddy says:
Imagine having a child who comes home with tattoos like that!
I think I would emigrate
kelsey says:
You have emigrated Raddy
ha ha ha 🙂
Simon
Love this “Bale and Aguero for Chamberlain and Welbeck! ”
Like me, you’re a big thinker aren’t you? 🙂
Unfortunately, some of the English players like Gibbs, Theo, and Ox are flattering to deceive at the highest level. I don’t think they’re good enough to win us trophies. Wilshere also because hes too injury prone.
We need more players like Nacho, Alexis, Campbell at the moment, Coquelin…then I’m sure we won’t see results like we’ve had the last 3 weeks.
And for God’s sake AW play Elneny, play Gabriel – leave BFG as backup, and Flamini and Arteta as a last resort.
Hi Oz
I’ve never seen Elneny play, so hard to comment, but I’m guessing it’ll take him a few weeks on the training pitch to get to know the chaps and how they operate
Hi Oz, I have no doubt AW will play Elneny as soon as he is in tune with the team – probably against Burnley this Saturday.
Gibbs surely has to be the best second choice LB in the prem don’t you think.
I guess this is Mert’s last season as 1st choice CB. I agree The Ox is yet to realise his potential and certainly Theo is leaving it late 🙂
🙂 ditto Micky
Cheers. I think the obvious place for a first team marquee upgrade is on the right attacking position. There are not many of those about though. We also have an issue in teh central midfield role beyond Cazorla. Here’s hoping Ramsey balances his game or Elneny steps up.
Hi again Simon, well if you believe today’s reports, then you may be getting your wish ….. apparently we’ve done the deal for Yarmalenko for £23m. I wouldn’t hold your breath at this stage, but he can play anywhere across the front three.
http://www.msn.com/en-gb/sport/transfers/arsenal-agree-fee-for-yarmolenko/ar-BBoMJxa?li=AAaeUIW&ocid=mailsignoutmd
Let us look at our A squad:
Cech – Awesome
Bellerin – Great
BFG – Close to Very Good but not great
Kos – Great
Monreal – Very Good
Coquelin – Very Good
Ramsey – Great
Ozil – Awesome
Walcott -Very Good
Giroud – Very Good
Sanchez – Awesome
To win a league – you want mostly Great and Awesome and you can live with 2 very good as starters
So I would say:
-> Priority is a CB
-> If we can fund a right winger or a striker at level GREAT or AWESOME, this would be the second priority BUT then you sell either Walcott or Ox or Campbell
Now, the issue is more related to our bench where you want very good mostly:
Ospina – Very Good
Debuchy – Good
Chambers – Good
Paulista – Good
Gibbs – Good
Flamini – Good
El Neny – Very Good (let us be optimistic)
Wilshere – Very good (when he is fit)
Ox – Very Good (when he wants)
Wellbeck – Very Good (when he is fit)
Campbell or Cazorla – Very Good to Great
I am getting rid of the Artetas and Rosickys and if we wanted to make some money, I would also sell Cazorla but only in Spain or Germany or France or Italy – not to an EPL club.
We can get an upgrade on Debuchy
We can get an upgrade on Gibbs as well
We can get an upgrade on Chambers (we loan him out)
We can get an upgrade on Flamini
So here is my shopping list:
CB: Garay, Marquinhos, Laporte, Pepe
RB: Coleman, Aurier
LB: Baines
DM: Veloso
RW/F: Reuss, Meertens, Willian
Hi RC78: I’d add that while many are individually ‘great’ our game needs a certain type of player. Our midfield without Cazorla playing with Coquelin has been weak: we need a new balance and so far it hasnt been Ramsey. Same problem on the right with Theo.
Reus is amazing but mainly on the left where Sanchez plays and I’d not bother upgrading on Sanchez! (unless you see him as an upgrade on Giroud/Walcott as a striker).
My shopping list of ‘not going to happens but not completely insane’ is Aubamayang (Great moving up to awesome?), Reus – if he can play as well on right as left (awesome – he cant get into the Barca team and he is barred from Real), Pogba (awesome, c’mon we can give him 6 times his current wage!) , Varane (awsome, not playing but I guess wont be sold…). The right is the problem and we are not getting Bale!
Good piece, but – unless I missed him – I think you’ve forgotten Jon Toral. Don’t underestimate him…..good at Brentford last season and tearing it up at Birmingham this (have you SEEN his latest goal – fab !!).
Thanks NBL, damn, I should have remembered Jon Toral. Yes I saw that goal it was superb. We brought him in from Barca at the same time as Bellerin I remember. Still he would be another attacking midfielder to add to the already lengthy list 🙂
Rasp. darling, I absolutely love that Post – it is a proper Post, analytically thought out, cleverly written and well researched – a big thank you for the time and effort you have put in! 😀
The didactic headline first caught my eye – and I skipped to the bottom of the essay to see who the author was – and almost spilled my coffee to see it was you. 🙂
Yes, best of mates with Hector Bellerin, so to have them in the same squad would be beneficial to both I would think. I think Wenger might bring him back into the fold next season.
Hi Rasp, excellent bit of work. This is obviously one you haven’t just hashed up earlier and have been developing for a bit. The graphs are excellent. I don’t know what a pedant is so I am not sure if I am one. However, you have obviously c-cked up the midfield section and should have asked me first, but that is just me being a bit pedantic 🙂
I really echo what I said yesterday in that I don’t think we need further additions to win this years EPL but will likely need them to challenge in future seasons (when I expect the Chav’s Citeh and Utd will be far stronger than this season) and we certainly need those world class additions to challenge at the top end of Europe.
We really only need about 2-3 big purchases to give us what we need to challenge for 4-5 seasons, so why not blow a lot on each one. As your graph points out Rasp we have so many top players in the right age bracket, and so many promising ones coming through, that we would likely only need 1 TW of big spending and then probably have a few seasons where only moderate spending is required.
I am calm about this being in the summer though if January is too hard to get the right ones.
I like Raddy’s idea on Stones and Bale. Currently the striker is such an unanswered position that you have to say buy buy buy Arsene. As I said yesterday the fact that Giroud is our first choice striker after 4 years worries me a tad as to where Arsene sees us going with this position.
Walcott it seems has been tried in that position for a few games and obviously deemed a failure in it, that conclusion being reached by way of fact that he is now back on the wings.
I agree about Welbeck potentially having all the skill sets to be a top striker that is also suited to the more physical EPL. Even at Utd and with England he has been played wide a lot, so he hasn’t really had his chance properly. I adhere to the opinion that a player needs a run of games at striker before you can assess what level they can get to, not bit parts here and there.
When Welbeck has played as a striker he hasn’t disappointed me, and I feel the team performances (as much as individual goal stats) were impressive with him up top.
Where I am not too sure I agree is in this sentiment that AW is just waiting for Welbeck to come back and give him a run of games as striker, as AW sees him as being the one. It conveniently ignores the fact that there have been a number of games (pre Welbeck injury) where he was played wide to again accommodate Giroud as the striker.
That doesn’t strike me as the actions of a man that has big plans for Welbeck as striker. Opportunities to play Welbeck and Walcott as striker have come and gone. Reading between the lines that says to me that AW doesn’t see them either becoming top strikers. I wouldn’t hold my breath that Welbeck will be given that opportunity under AW, as recent history points in another direction.
The only question after that for me is does AW believe Ollie is the top first choice striker we need? 4 years on from his arrival would tend to suggest so, as that is a lot of time and games to assess a player. Conclusions must have been reached because it is also ample time to have either sourced someone else, or to promote someone else from within and give them a longer run of games in the position.
I speed read the Post first, which is normally my wont, and then went back to read it again, and intellectually there was indeed nothing material that I could find with which I would disagree.
But — and be fair, you would be disappointed if there wasn’t a big, fat ‘but’ – 🙂 – in the same way that I look forward to prezzies at Xmas, even if they are totally unnecessary or even appropriate, I would be happy – no. I would be ecstatically happy – if we (Arsenal) bought half a dozen top quality players – and while trying not to be too like Mickish – if 60% of them were strikers I would elevate ‘happy’ to a paroxysm of ineluctable delight!! 😀
That, of course, will not happen – and as you say it is really not necessary – so if some fans allow themselves to dream of buying Messi, Ronaldo, Aguero or similar, I have no complaints, because they know they are just moon gazing, and most of us are realistic enough to accept that the best judge of Arsenal’s player needs, it is Arsene!
Very enjoyable read and love the chart, Rasp !……..it is the chart`s “Strkers front 3” which is your achilles heal !…….”Front 3″…you have 5, one is on loan and one is in a Diabyesque Coma, leaving just 3, this is not adequate for a team currently battling 3 trophy fronts !…….a strker….preferably the £100M kind….is what`s needed !.
Mansour City spent what…a £100m on two strikers in the last window ?….a statement of intent !….us ?….a goalie !……different mindset of a club wanting trophies at any cost to one which is happy to have the enormous amount of funds left in the bank !…..Mansour City, Manshafter and Chavs piss on us every time !….the latter two are having a poor season, does anyone seriously think their owners will accept that and not try to rectify it with some massive spending in the summer !.
With our £230M in bank, we are punching well below our weight !…..not decisive or aggressive enough !….we are frequently having sand kicked in our faces by them three that we could supply Jewsons enough sand to build the Spuds new stadium and then they can kick sand in our faces as well !.
Hi Redders and GB. It’s not easy being a virtual manager is it? 🙂
I agree GB, I’m sure Arsene isn’t planning to give Welby the CF spot for the rest of the season, but he can play as part of the front 3 if only as a sub. The first challenge is to keep him fit.
Redders, I too love a new signing. P.E.A. is the one I’d like to see, but you must be overjoyed at the stories linking us to your man Yarmalenko
Hi Cockie, I’m sure you realised that I meant a player who can play CF or anywhere across the front 3. We currently have 3 – 5 of those. I suspect that number will increase to 6 in the summer 🙂
Rasper,
My joy would be unbounded if we get Yarmolenko, 😀 but I was (privately) gutted when last summer’s rumours proved unfounded – now he would be a superb buy – in my opinion! 🙂
Seen vids of Redders heart throb Yarmalenko and he look as bout as skilfull as they get !…….I wonder if he has Arshavins workrate ?.
He’s 8.5 inches taller than Arshavin 🙂
Dont talk to me I`m in the middle of 3 X 5 minute planks !…………..I`m in pain !.
Mind you…..even as a plank I`m quicker than Arshavin ! hahaha
Wellcrocked is out of the coma !
Arsene news !
“Mertesacker is out because of the red card, and everybody else is available, apart from Jack Wilshere and Santi Cazorla,” he told the club’s official website. “After that it is just a question of selection and decision-making, that is the key. “Jack and Santi are progressing well but they are at least a few weeks away. But these two apart, it is just about competitiveness and match fitness. “Danny Welbeck is not completely ready but he is not far. He needs a game or two because he’s been out since last April. The Stoke [under-21] game is too soon because he only had one session with the team, and that is too short. “Francis is available to play now because he has passed two weeks of full training. Tomas (Rosicky) is also available for selection.”
Well it will be easy to convince you (especially come may). In a man city – arsenal combined team would any city players get on? If the answer is yes (and it is don’t be deluded) then arsenal could do with a stronger player in that position. Arsenal fan by the way. Apparently we have 70 million in the bank. Let’s see a left winger cos we have no true left wingers at the club (Sanchez is best at right and scores twice as many there than the left so don’t start) Cavani for 35 million (I believe giroud is good but how many through balls is ozil not allowed to make because of poor pace) nolito 13ish million buy out clause, carvahlo/wanyama with the rest. Keep giroud as a good option but cavani (although will miss the odd sitter) has scored bucket loads wherever he’s been at not as much for PSG but a good return for playing as a winger.
Cavani wants to play CF so he will not join a team as LF…
By the way – excellent post!
Ahhh meee, welcome. Man City are on equal points with Arsenal. I reckon a combined team would be about 50/50 . Certainly Koscielny, Bellerin, Ozil, Sanchez and maybe Ramsey, Monreal and Cech from Arsenal.
Apparently we have more than 70m in the bank, but that’s not the point. The cost of any player is the original fee plus the wages over the period of the contract. A £50m player on 150k a week over 4 years costs the club £92m.
Aubameyang can play on the left and is a much better option than Cavani due to his age and versatility IMO. As RC78 says, Cavani wants to play in the middle, that is why he was unhappy playing second fiddle to Ibrahimovic
I have no problem with Cavani playing in the middle if he arrived at us. I also agree with Redders opinion that Yarmolenko would be a great signing.
AW likes a striker (apart from the last 4 years) that has a wingers ability to give them more all round skills and allows them to move laterally into wide positions at times, and link up well. Cavani would fit the bill but maybe Yarmolenko (if he does come) could be earmarked for conversion to striker. He seems to have the physical attributes.
Ahhh Meee, afraid I have to totally disagree with Sanchez from the right.You think he would double his tally from the right, I think he would halve it. Wide players always score more coming infield on their favoured foot. Ask yourself why Bayern, Barca and Madrid all play with lefties on the right and righties on the left? It is too increase the overall goal tally and have 3 high contributing goal-scorers, rather than 1 prolific 1 up top.
Top post, Rasp, thanks.
Not really my area of expertise maybe.
Love the chart.
What a load of bolleux, of course it is your area Chas. Get typing with your analysis toute de suite. Doesn’t excuse you from film clips tomorrow though.
Did someone mention Cavani?
And did someone mention us buying whatshisname RA was on about for 26M?
Back in 30 mins 🙂
I was expecting a slight diversion to include the news that the ‘big’ clubs are trying to improve (rig?) the CL to ensure the ‘big’ clubs from each of the major leagues get permanent entry to the CL.
This would be going the way of a franchise set up like the NFL – or even a European super league, if it is accepted, and I suppose it is the major clubs sniffing the money.
Question is — who is a ‘big club’ entitled to get into such a set up?
Manure, Liverpool, Chelsea, Man Citeh, Spuds, Arsenal? No numbers agreed yet, but 4 seems to be the magic number – just exploratory – but there will be one hell of a row, whoever gets in.
It will change the face of football as we know it, and anyone on the outside looking in will be pretty peed off.
Just saying.
Interesting stuff Redders, got a link to this news/rumour ?………………on current years in CL it has to be Manshafter and Arsenal with Dippers, Chavs and Mansour City fighting it out for other two places …………………………………..expect some backhanders and bribery even with such high scrutiny going on in the world of sport !
Rasper,
I have been ‘moon gazing’ myself, on and off this afternoon, about the possibility of Yarmie joining us in the summer.
The problem is tho’ that 2 or 3 years ago we were supposed to be trying to do a deal and got close, but there were so many part owners involved, as well as his club, that it proved impossible to get agreement with all of them – and the talks folded.
Not sure why that has changed now – or even if it has – but GB, who has wormed his way into my affections, and of course Corky the Camel, would be able to see the difference and why a tall, really fast, two footed, goal scoring, attacking winger has made me pant for such a player to join Arsenal, and he would see why lovely Theo, whom I genuinely like as a person, is just not in the same league — well literally at the moment! 😀
Telling you that has made me realise it probably won’t happen. 😦
Cookie-Doodle,
There is no link as such, but the story was mentioned briefly by the BBC at 5:30 a.m. this morning, but talked up extensively on TalkSport this morning when I was out and about.
They were pretty horrified by it as one of the chat ‘guests’ was Danny Murphy and he was concerned that the Spuds and maybe both Everton and Pool would miss out.
It seems that UEFA have had preliminary talks with Manure and Juventus representing the ‘top clubs’ saying they needed to move on and take the opportunity of marketing top European football worldwide [and altho it was not mentioned, I think they want shot of Platini’s election bribe to the smaller countries/ leagues that they would be included in the group stages of the CL, if they voted for him, allegedly, because they are just fodder to be bumped off by the bigger clubs in every tournament, and the games are boring.
Let’s face it – the TV companies are probably behind this, and they want value for all the money they have poured into the CL – and when money talks – everyone jumps, especially UEFA, I suspect! 😀
Something like this was always going to happen, at sometime in the near future.
We will see.
Lad lads lads, stop
That’s a post right there. Someone copy, paste and delete now
Agree. That would make a very interesting topic for a post..
If I understood the details I would write it but …
Well Erik, looks like we managed to stop that interesting chat in its tracks
Have we done a bad, or will RA be furiously penning an AA hit record post 🙂
I’m out, can someone do the copy cut and pasting pls
Personally, I’ve got an urge for a pizza
I am rustling up a BLT toasted sandwich.
Urrr Rasp, do you mean highlight, control a, control c, open word doc, control v?
I always used to think a pint of bloody mary went rather well with a club sarni as long as you had a side order of crisps
Right, off to youtube this Yarmolenko fellow
Nice one Rasp
I agree, no more signings. We have enough players as it is. I want the squad reduced not increased., I can hardly remember the players names there’s so many of them . I don’t want people to think ime senile? That’s when they come for your money
I will tell you about something that happened to me a few years back Rasp
I was El Presidente of the local Subbuteo and those who enjoy watching spiders consume flies club.
One day this good looking bastard with an expensive suit came knocking saying he wanted to join. The others didn’t want him, there were rumours that he once dated a girl, but I was taken in by his discreet chat that he had a Tarantula and had just received by post a Japanese Grasshopper.
It was a foolish mistake. He soon caused friction by winding up the others of tales how on one occasion, he didn’t just talk to a girl, he kissed her and she wanted it.
He then came after me. Producing a silly statistical table , bit likes yours, that showed of all opponents Subbuteto players trodden on, I was responsible for a third.
I tried to argue it was because I wear height increasing shoes, but then he came out with a heinous lie that I had ruined his Tarantulas dinner by treading on the Grasshopper.
I was finnished after that. The only consolation was a few years later I ran into a couple of other members at a Keith Chequin book signing and they told me they threw him out after finding he did not live with his mother.
This is what might happen to Arsenal. Disruption, disharmony, and a danger to leaping insects.
What’s this about a closed European shop for big clubs? I can’t see Arsene agreeing to that. Football is about competition, dreaming of the Highbury turf, and Liam Brady. Not some private members club for rich twats suffering from gout.
I won’t have it. Jumpers for goal posts you Bastards.
I have just seen Micky and Raddy suggesting my comment could be used as a Post tomorrow.
If someone among the masters would like to squelch it, and let me know on AA, I could rework it as a Post tomorrow morning.
Won’t take long. 😉
You are totally barmy, Terry, and I love you!! 🙂
Transplant
Superb story. Has the lot. Height increasing footwear. Keith Chequin book signing. Nothing left out 🙂
RA
I can’t squelch, but add a juicy title, and the record is yours with that little number 🙂
Mickish,
If one of the AA powers is around tomorrow morning – all they need to do is let me know they want a reworked post and I will do it.
Radish’s dereliction of squelching duties in favour of a BLT sandwich is noted.
You know me – I’m not too bright, but I have fast fingers for post writing now that I have taught myself to type properly.
Don’t want a secretary do you? 😀
RA. I can’t squelch either but get writing and add a rant as it’s Friday 🙂
Hi RA, sorry, I just got home. Yes of course we’d like some Redders’ Therapy tomorrow 🙂
Divine madness from you as usual Terry 😆
Just to be clear, mine isn’t really a silly statistical table, more just a silly table because the data presented is factual and not open to misinterpretation 🙂
RA
I’m going to have to say no to the secretary offer. I’m sure you’d look stunning in heels and inappropriate office attire, so I may well live to regret the decision 🙂
Erik
I don’t think we need a rant, as it’s a very sensible and interesting topic.
However, if you’re angry about something, you can quietly let off steam in the corner and we won’t mind. Any newcomers to the site tomorrow may give you an odd look, but hey, cloak hood up and press on would be my advice
Rasp
It was the best homemade chart we’ve ever had, so don’t dis your work 🙂
Much appreciated it was. Genuinely.
Wasn’t that impressed by the Yarmolenko youtube vids
Big, fairly fast and a good left shot, but somehow the opposition defence always looked a bit…urr…accommodating
Still, that’s why he’s only worth 23M I guess
Thanks Micky, it was good to see comments from some new readers. if you look at the bottom of the post you will see it was ‘liked’ by a guy called Mike Steeden. He often ‘likes’ our posts and if you click on his avatar you will see he’s an interesting guy – it would be great if he joined us in comments.
hahaha, I really liked the chart Rasp, probably the best one we’ve ever had. However, I threw the quip in because you were getting to much praise, and been a friend I did not wish your ego to threaten your sanity
Rasper,
Just popped back and saw your comment – so give me 10 minutes and I will cobble something together for you. 🙂
Ta Redders 🙂
OK, Rasper,
I have stuck it on the end of Micky’s Post yesterday.
No apologies for the quality – I have had two unexpected visitors – got to go!! 😀
Thanks Redders’. I’ve locked it away for tomorrow 🙂
Just one quality slider and I’ll slip away happy
Morning deer 😉
So Debuchy is going to Sunderland or Villa so in my eyes despite the rise of Bellerin he wasn’t a good buy for us as he has dropped down the ladder dramatically.
Ahhh very good Crystals
As in the ones I murder for fun 🙄
I think Debs was a good buy, just Bellerin turned out to be outstanding 🙂
1.

2.

3.

4.

5.
there you are micky, a polish cat
what were the titles yesterday?
Barbarella
Where Eagles Dare
Bedknobs and Broomsticks
Lost in Translation
If
4 true romance 🙂
Last film thingy today – it’s been done to death.
Morning all,
3. is one of my favourite films of recent years … No country for old men
3 i know that film, a psycho killer goes shooting people
Is 2. Rollerball?
Correct Eddie 🙂
5. Bridge over the river kwai?
Now you all rock up
Out now ’till mid morning
Really looking forward to todays post
Thanks Chas and Eddie
oh no Chas, please don’t quit, it is great morning fun
legs have to be some Bond movie
Just number 1 to get.
Loving that post Rasp, as well as highlighting where we are currently it also highlights the squad management needed to keep consistency.
The next round of departures are likely to be on the older side of our squad, that will mean we have to invest in the 23-30 bracket.
In a ideal world you’d have three teams progressing through the ranks at any time, all of similar age in their teams….so
One group at 27/28, one at 23/24 and one at 18/19 for arguments sake.
The progression just becomes natural and routine. The problem in doing this is you’ll have players coming through the ranks who are good enough but fall in between the age ranges when their time comes to be named.
I am worried by some of the names that some people seem to want to push out. The likes of Gibbs, Ox have a value that a foreign import (and for ECL rules even a domestic import) doesn’t bring….they are club homegrown, we need 4 of them to be able to name a 25 man squad for Champions League. Hector also counts, as do Theo, Jack and Rambo.
United built Championship winning teams with such illustrious named as O’Shea, Brown, Fletcher etc. They give their all for the club they love and require much lower wages than a new import would who needs to be convinced it’s worth coming to bench warm.
Another silly idea was TV programmes, but they all seem to be from a particular vintage. 🙂
One off
1.

2.

3.

4.

5.

Sorry, GIE, I didn’t realise anyone was going to come on and say something relevant to yesterday’s excellent post. 😦
Valid point about the homegrown rule.
It’s a good job the Arsenal management seem to plan not just for the short-term.
oh no, i won’t know any of those, i was in Poland then 😦
Anyway, the JTW almost shut and we still haven’t got a striker. Wenger is allegedly stalking Hull City’s Abel Hernandez. I don’t believe it.
Morning All,
1. Can’t remember the movie but i s it that unforgettable scene when Jamie Lee Curtis goes into the bedroom with Arnie?
2. Rollerball?
3. No Country
4. True Romance
5. Bridge of River Kwai
Chas. If this is to be the last film quiz I want to say thank you for taking the time to entertain us. Maybe something else in future?
1. Lost in space?
4. Citizen smith?
✔
✔
✔
✔
✔
Rasp
✔
4. 😆
Morning GiE,yes, most of the players coming to the end of their contracts are 33+ and the promising youngsters are either on the verge of the first team or out on loan – so good squad management I think.
I’m no expert on the academy, but I can’t name many defenders who are coming up through the ranks?
GiE – United now have Rooney who demands more, and more, and more. Brown, O’shea and Fletcher were from the old school, before silly money started to circulate. We had Parlour, Adams, Seaman too. Those were different times in football.
I like both Ox and Gibbs, Gibbs probably more than ;Ox and I don’t want them to leave the club, but they have to go on loan and play every game. Otherwise we will never know their true potential
5. Batman?
Wenger doesn’t do defenders, only inherits them. 🙂
Though I’d imagine Micky would say that Wenger doesn’t do strikers. 🙂
✔
Character name?
Fantastic comment from Terry last night. Really made me laugh this morning.
Keith Chegwin signing 😀 😀
4. Mork and Mindy (Robin Williams)
I think Gibbs is doing really well and I’m quite surprised he is happy to play second fiddle, particularly since Nacho signed a new contract.
I like The Ox. He is clearly being given his chance by AW but must be aware that we have 2 or 3 very good young pretenders coming through who will challenge him if he cannot become more consistent.
2. Bewitched
This came up in conversation yesterday – I bet kelsey remembers it. 🙂
Scary!
2. I dream of Genie?
Of course, Bewitched 🙂
Only number 3 to get for the TV shows.
Beggar my neighbour?
So what is the first film?
Bill and Ben – sigh.
They look a bit like West Country skinheads.
True Lies
LB’s going to download it on Netflics right now 😆
and what was the film with Dolls with bloody lips?
Put this into youtube search box
Jamie Lee Curtis ” Правдивая ложь “
This lady fueled a lot of young men’s fantasies … One for sorrow
Barbarella
OK, you trumped me there chas 🙂
Torchy the Battery Boy is my first TV memory. Alongside Hoppity and someone who used to swing on a farm gate.
And Pussy Cat Willum which is the reason I don’t like the little fluffy bastards
The Rag Trade
😆
I don’t remember BArbarella like that!! Looks complete crap
Willum !! Not seen him in half a century – still don’t like him
Ahh, silly me, totally forgot, a still earn a small part of my living from that film.
For the music, LB?
kelsey
I just looked it up and June Whitfield was only in one episode of the Rag Trade. What a good memory you have!
It was Beggar My Neighbour.
OK Chas. I am convinced.
No, BR, you’re right, it is a crap film with only one saving grace.
I only watched No Country For Old men for the first time the other day and loved it.
No idea how it slipped under my radar, though I do love it when someone recommends a film and I sit transfixed.
chas. Dildando??
Yep
Anyone believe the Chilwell from Leicester rumours?
If we are looking for a Boosh replacememnt why sign a 19 y.o who will want some pitch time and a career?
Chas, yep
Heard a rumour that Redders has put a post for today somewhere ……. anyone know where?
Drafts?
Yes in drafts ……….. silly me
New Post ……………….